MemoRAG - 기억하는 모델을 만들자
요약
- 인간은 공부를 어떻게 하는가? 교과서 등에 있는 내용을 학습하며 기억하고, 정확한 정보가 필요하다면 나중에 교과서를 찾아본다.
- 근데 RAG는? 공부는 안하고 매번 찾아본다.
- 공부를 안했으니 잘 찾을리가 없다!
- MemoRAG는 "기억하는 모델"을 학습시켜서 문서를 더 잘 찾고, 결국 대답을 더 잘하게끔 하는 구조를 제안한다.
왜 필요한가?
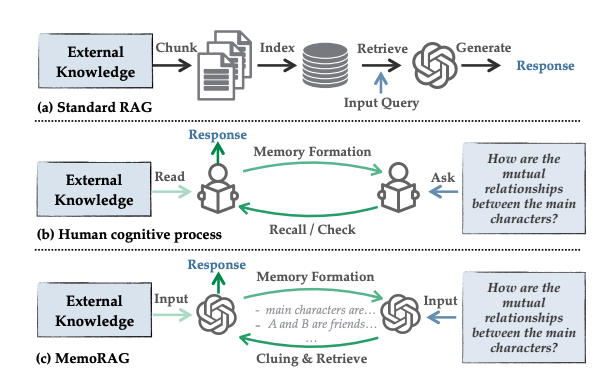
(a)부터 보자. 평범한 RAG이다. 어떤 문서들이 있으면, 적당한 길이로 청킹을 수행하고, 그것을 임베딩 모델 등을 통하여 Vector DB에 저장한다. 이후, 입력 쿼리에 대해 검색을 수행하고, 검색 결과를 바탕으로 LLM이 답변을 생성한다.
이러한 과정은 (b)에서 표현하는, 인간의 학습 과정과 매우 다르다는 것이다. 인간은 모든 문서를 "읽어보고 기억"할 것이다. 문자 그대로 기억하기보다는, 어떤 추상화된 지식으로 기억하게 된다.
이렇게 "한 번 읽어본" 내용들에 대한 질문이 들어오면, 그 기억을 기초로 해서 정확한 내용을 문서 더미에서 찾아볼 수 있었다.
마치, "아 그그그그그그 거기에 있었던 것 같은데??" 하면서 찾아보는 것을 생각해보자.
이 과정을 비슷하게 구현해보자는 것이 바로 (c) MemoRAG이다. 어떤 Memory Model에 문서 내용들을 넣어 기억하게 한다.
이후 해당 내용에 대한 질문이 들어오면, "기억나는" 대로 단서들을 생성해낸다. 이제 그 단서들로 문서 검색을 수행한다.
이렇게 Memory Model을 활용하면 1) 명료한 질문, 2) 잘 정리된 사전 지식 corpus가 없어도 성공적으로 정보를 가져와서 좋은 답변을 생성할 수 있다!
Memory Model 만드는 법
어디에 "기억"을 저장할까? 논문에서는 KV cache를 택한다.
KV cache란? 트랜스포머 각 레이어 각 헤드의 어텐션에 Key와 Value 값들을 의미한다.
즉, 어떤 input
이해가 안된다면 트랜스포머에 대해서 공부하고 와야만 한다.
-1.jpg)
조잡하지만 이해를 돕기 위해 그려보았다. 더 쉽게 그리려면 엄청난 노력이 들 것이라, 양해를 구한다.
일단 첫 번째 특징, Memory Token이다.
특정 문서의 정보를 저장하고 싶으면, 그 정보 뒤에 특수한 Memory Token을 넣어준다. 위 그림에서는 [MEM] 이라고 정해보았다.
해당 Memory Token에는 기존 모델의 Q,K,V 가중치가 적용되지 않고 새로운 Q, K, V Memory 가중치가 적용된다. 이 가중치들이 Memory Model에서 유일하게 훈련되는 가중치들이다.
이제 두 번째 특징, 어텐션 연산 시에 KV cache를 활용하는 것이다. 위 그림에 나온것처럼, Query의 경우는 query vector들 앞에 새로운 것이 추가되지 않는다.
하지만, Key와 Value의 경우에는 각각의 cache vector들이 추가된다. (그림에서 각각 초록색, 파란색 벡터)
이 cache vector들이 뭐냐고? 바로 "이전 문서"들에 대한 기억이 되겠다. 어떤 문서 더미를 읽히고 memory 토큰을 통해, 그 메모리 토큰에 해당되는 Key와 Value 값들이 만들어진다. 이 만들어진 KV 값이 Cache에 추가되는 것이다. (추가는 add가 아닌 concat이다. 즉, memory 토큰이 4개였다면 4만큼 cache의 길이가 늘어난다)
그렇게 KV cache를 포함해서 attention 연산을 수행한다.
즉, Memory 가중치를 통해 문서의 내용을 KV cache로 압축하고, 그 KV cache들을 모아서 하나의 기억 저장소를 만들어내는 것이다!
MemoRAG
그러면 Memory Model과 함께 RAG를 수행할 수 있다. 과정은 다음과 같다.
- Memory Model을 주어진 문서들을 이용해서 훈련시킨다.
- 유저의 질문이 들어오면, Memory Model을 통해 어떤 단서들을 생성한다.
- 이 단서들을 토대로 Retriever에 검색을 한다.
- 검색해서 나온 문서들과 쿼리를 LLM에 넣어 답변을 생성한다.
끝!
Memory Model 훈련법
중요한 점은 어떻게 Memory Model을 훈련하는지가 되겠다.
1. Pre-training
먼저 pre-training을 수행한다. 이 단계는 새로 추가한 Memory Weight 들이 정상적으로 동작하기 위한 토대가 된다. 그래서 딱히 기억시킬 문서로 하지 않고, RedPajama와 같은 일반 텍스트 corpus를 다량으로 넣어 학습시킨다.
학습 방법은 그냥 next token prediction인데, KV cache를 앞에 넣어서 학습시킨다는 점이 다르다.
논문에서는 2억 토큰의 RedPajama 데이터셋으로 훈련했다.
2. SFT
먼저, 고성능 LLM을 통하여 문서에 대해 질문과 정답 쌍을 생성한다.
그 이후에, 질문 - 문서의 단락 - 정답 조합을 주고 "정답 단서"를 생성하도록 한다.
이제 질문과 KV cache를 이용하여 올바른 "정답 단서"를 생성하도록 훈련된다.
논문에서는 17,116개의 샘플들을 이용해 SFT를 수행했다.
3. RLGF
RL을 수행하는데, 여기서 "Generator Feedback", 즉 실제 정답을 잘 생성할 수 있도록 생성한 정답으로부터 피드백을 받는다.
당연히 좋은 정답을 주었으면 높은 리워드를 주고, 좋은 정답에 대한 기준은 Task마다 다르게 설정해야 한다.
논문에서는 2,000개의 샘플들을 이용해 RLGF를 수행했다.
실험
NarrativeQA, Qasper, HotpotQA, MuSiQue, GovReport 등등의 여러 데이터셋을 평가했다.
Long-context LLM (Full, SelfExtend 등), Dense Retrieval (BGE-M3, Jina-emb-v3 등), Advanced RAG (HyDE, RQ-RAG 등)의 베이스라인과 성능을 비교하였다.
메트릭은 답변 정확도로, F1이나 ROUGE를 사용했다.
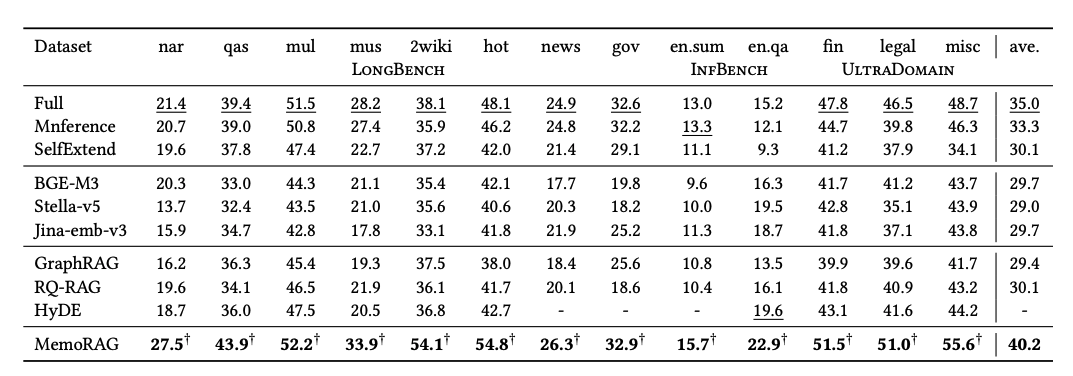
모든 데이터셋에서 MemoRAG가 가장 높은 성능을 보여준다.
그냥 Context 전체를 한 인퍼런스에 넣는 "Full"보다도 5점이 넘는 성능 향상을 보인 것이 놀랍다.
리뷰
- Trainable Parameter가 적지는 않다 - Qwen2-7B-Instruct 모델의 경우 메모리 모델 훈련에 1.1B 정도의 파라미터를 훈련했다고 한다.
- 결국 기억 = 훈련이다. RAG에 훈련이 들어가면 결국 "새로운 문서를 추가하려면?"이라는 문제가 생긴다. KV cache를 추가하면 되겠지만, Weight 조정 없이 새로운 문서에 대한 지식이 효과적으로 KV cache에 추가될 수 있을까?
- 결국 SFT 데이터셋을 잘 생성하는 것이 알파이자 오메가로 보인다. SFT 과정에서 KV cache를 활용하여 주어진 쿼리에 대해 단서를 생성하는 방법을 학습하는데, 이 데이터셋이 garbage라면? GIGO에 따라 학습이 잘 안될 것이다.
근데 실험에 사용된 잘 알려진 도메인이 아닌, 진짜 낯선 도메인이라면 이 SFT 데이터셋 구축 과정이 간단하지 않을 것이다. - 종합적으로 성능은 놀라우나 현업에서 감히 "써보자!"며 도입할 수 있는 방법론인지에는 물음표가 생긴다.